List of Publications
* – Equal Contribution
-
Zeeshan Khan*, Kartheek Akella, Vinay P. Namboodiri and C. V. Jawahar. More Parameters? No Thanks! Accepted at Findings of 59th ACL (Association of Computational Lingustics) 2021, Bangkok, Thailand (Online) [Detailed]
-
Kartheek Akella*, Sai Himal Allu*, Sridhar Suresh Ragupathi*, Aman Singhal, Zeeshan Khan, C. V. Jawahar and Vinay P. Namboodiri. Exploring Pair-Wise NMT for Indian Languages. Accepted at ICON (International Conference on Natural Language Processing) 2020, Patna, India (Online) [Detailed]
-
Sai Praveen Kadiyala, Kartheek Akella, Truong Huu Tram. Program Behavior Analysis and Clustering using Performance Counters. Accepted at DYNAMICS (DYnamic and Novel Advances in Machine Learning and Intelligent Cyber Security) part of ACSAC 2020, Austin, Texas (Online) [Detailed]
1 Paper is under peer review
Detailed Publications
 |
More Parameters? No Thanks! Abstract
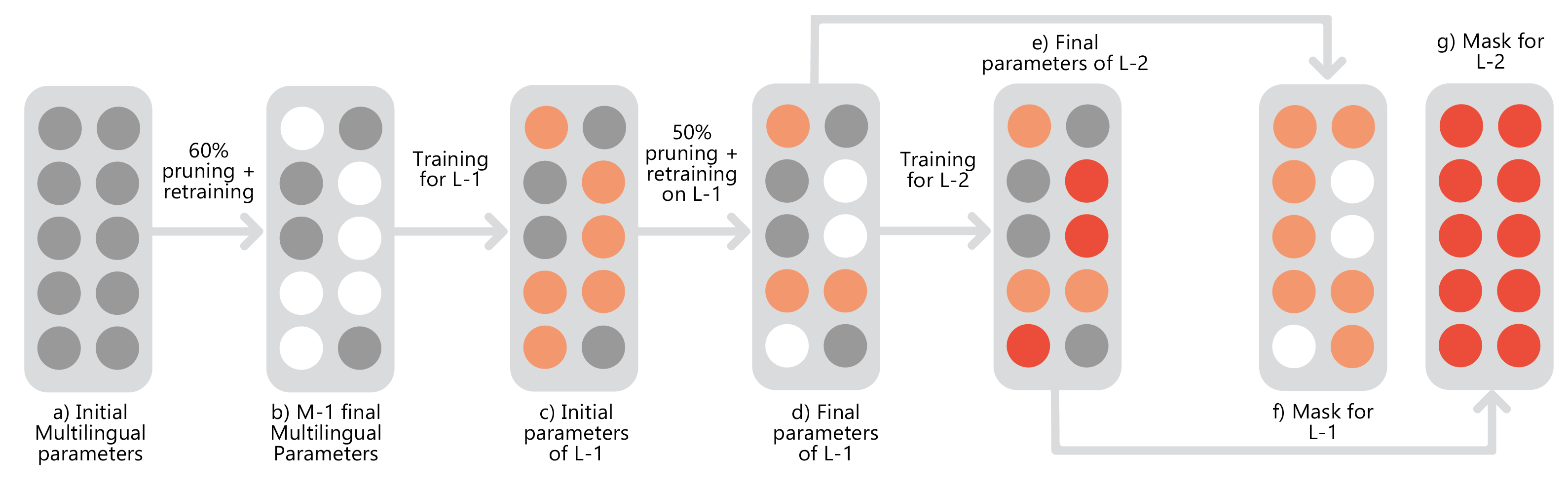
This work studies the long-standing problems of model capacity and negative interference in multilingual neural machine translation MNMT. We use network pruning techniques and observe that pruning 50-70% of the parameters from a trained MNMT model results only in a 0.29-1.98 drop in the BLEU score. Suggesting that there exist large redundancies even in MNMT models. These observations motivate us to use the redundant parameters and counter the interference problem efficiently. We propose a novel adaptation strategy, where we iteratively prune and retrain the redundant parameters of an MNMT to improve bilingual representations while retaining the multilinguality. Negative interference severely affects high resource languages, and our method alleviates it without any additional adapter modules. Hence, we call it parameter-free adaptation strategy, paving way for the efficient adaptation of MNMT. We demonstrate the effectiveness of our method on a 9 language MNMT trained on TED talks, and report an average improvement of +1.36 BLEU on high resource pairs. |
 |
Exploring Pair-Wise NMT for Indian Languages Abstract
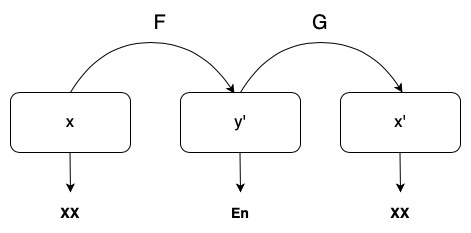
In this paper, we address the task of improving pair-wise machine translation for specific low resource Indian languages. Multilingual NMT models have demonstrated a reasonable amount of effectiveness on resource-poor languages. In this work, we show that the performance of these models can be significantly improved upon by using back-translation through a filtered back-translation process and subsequent fine-tuning on the limited pair-wise language corpora. The analysis in this paper suggests that this method can significantly improve a multilingual model's performance over its baseline, yielding state-of-the-art results for various Indian languages. |
 |
Program Behavior Analysis and Clustering using Performance Counters Abstract
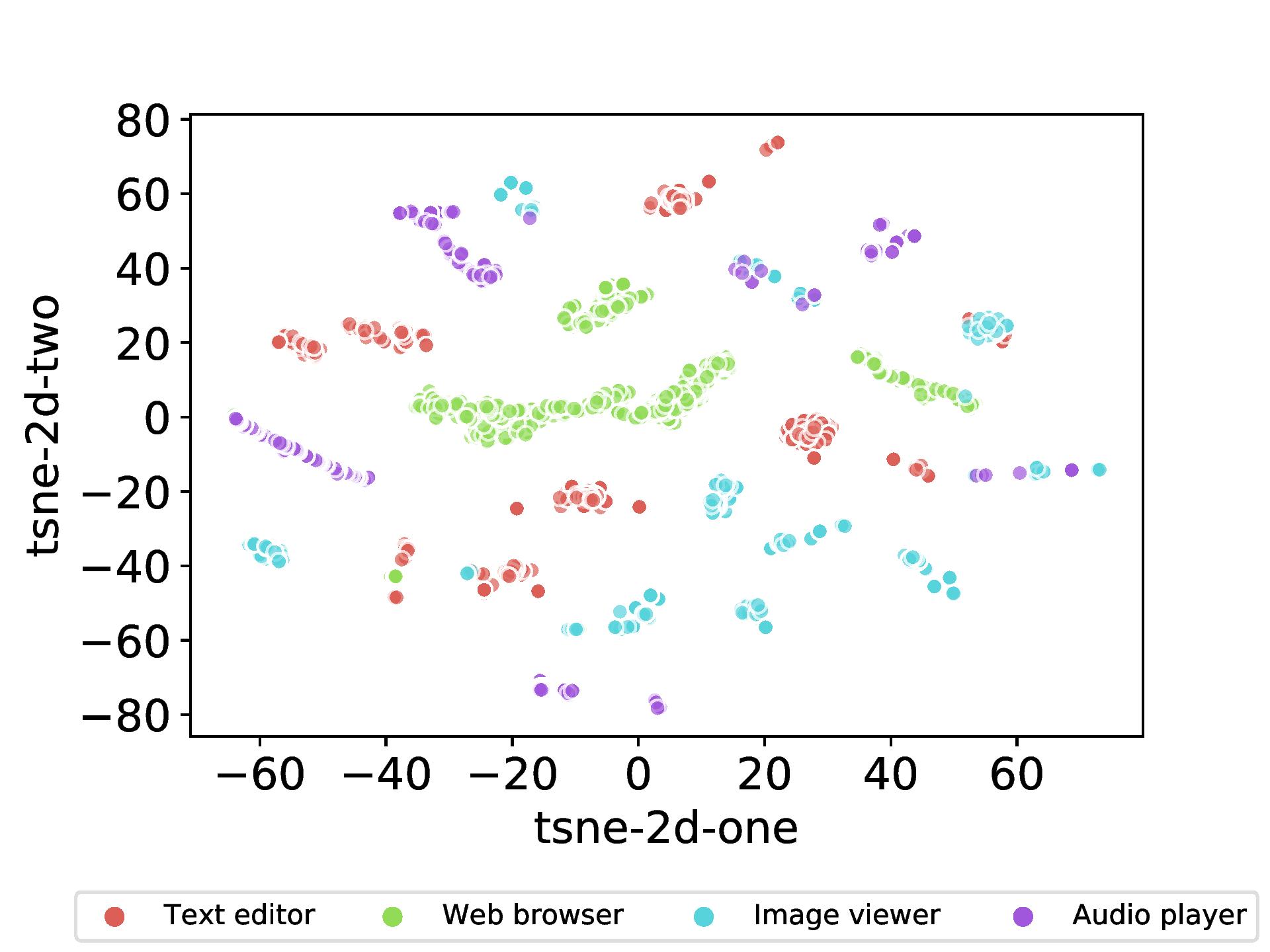
Understanding dynamic behavior of computer programs during normal working conditions is an important task, which has multiple security benefits such as development of a behavior-based anomaly detection, vulnerability discovery and patching. Existing works achieved this goal by collecting and analyzing various data including network traffic, system calls, instruction traces, etc. In this paper, we explore the use of a new type of data, performance counters, to analyze dynamic behavior of programs. Using existing primitives, we develop a tool named \texttt{perfextract} to capture data from different performance counters for a program during its startup time, thus forming multiple time series to represent the dynamic behavior of the program. We analyze the collected data and develop a clustering algorithm that allows us to classify each program using its performance counter time series into a specific group and to identify the intrinsic behavior of that group. We carry out extensive experiments with $18$ real world programs that belong to $4$ groups including web browsers, text editors, image viewers and audio players. The experimental results show that the examined programs can be accurately differentiated based on their performance counter data regardless whether programs are run in physical or virtual environments. |